Best practice
Trim and Change Case
Standardize text strings by using the functions
UPPER,
LOWER, or
PROPER
to set the case, along with
TRIM to eliminate any extra whitespace.
UPPER(TRIM('column_name'))
Strip out non-alphanumeric characters
Use the following regex with the setting ‘remove matched value’.
[^\w\s\d]
Combine Initials
Useful in company name matching. Use the following regex with the setting ‘Advanced: $1’.
\b(\S)\s+(?=\S\b)
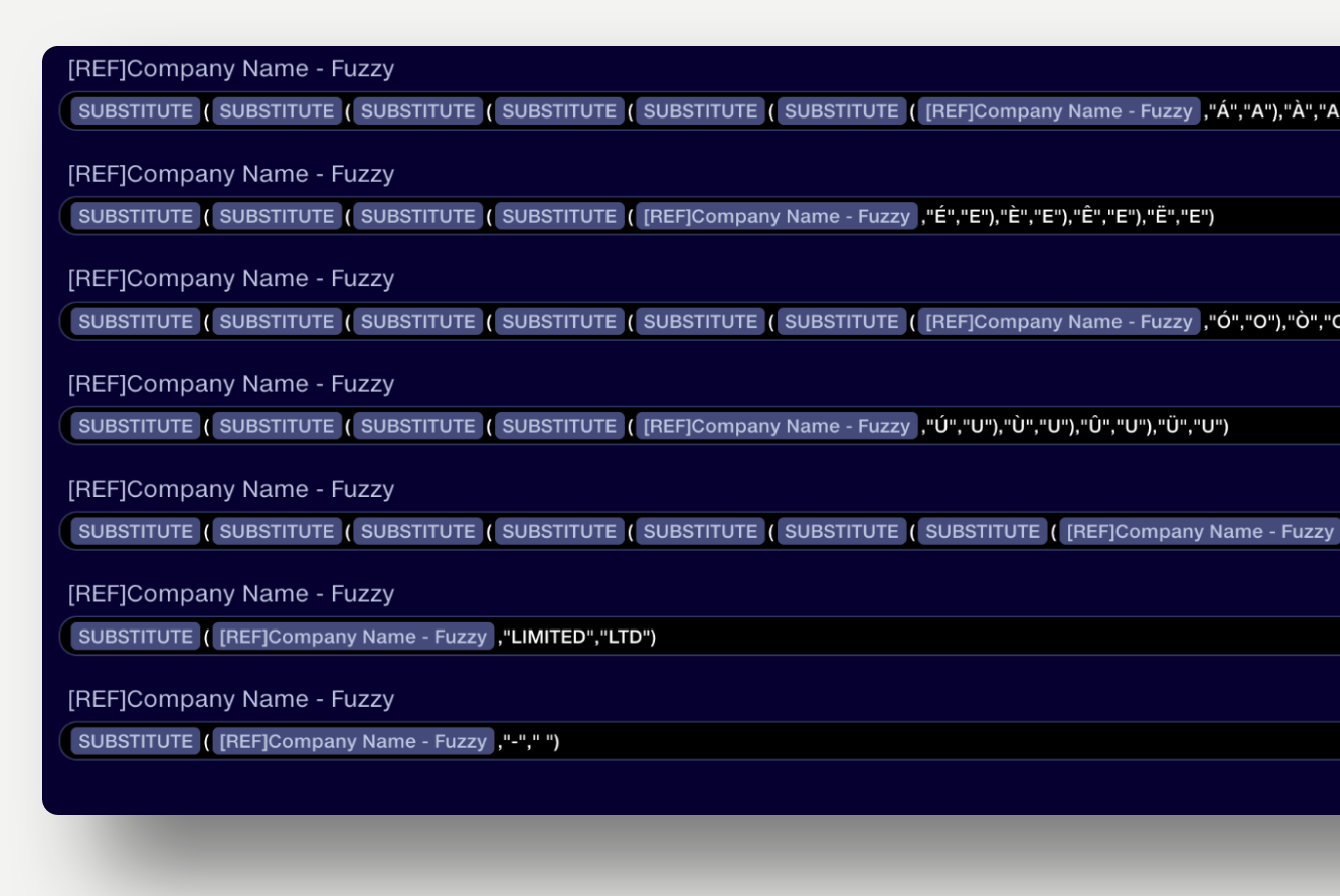
Remove accented characters
Run a series of
SUBSTITUTE
operations in Calculate to replace accented characters with a non-accented alternative.
Contact
support@quantemplate.com to have this set-up pre-built and dropped into one of your pipelines.
Add leading zeros before a number
For example, format a ‘Row Number’ column from 1, 2, 3, 4 to 00001, 00002, 00003, 00004. Use the following formula in Calculate:
RIGHT(CONCATENATE("00000", 'Row Number'), 5)
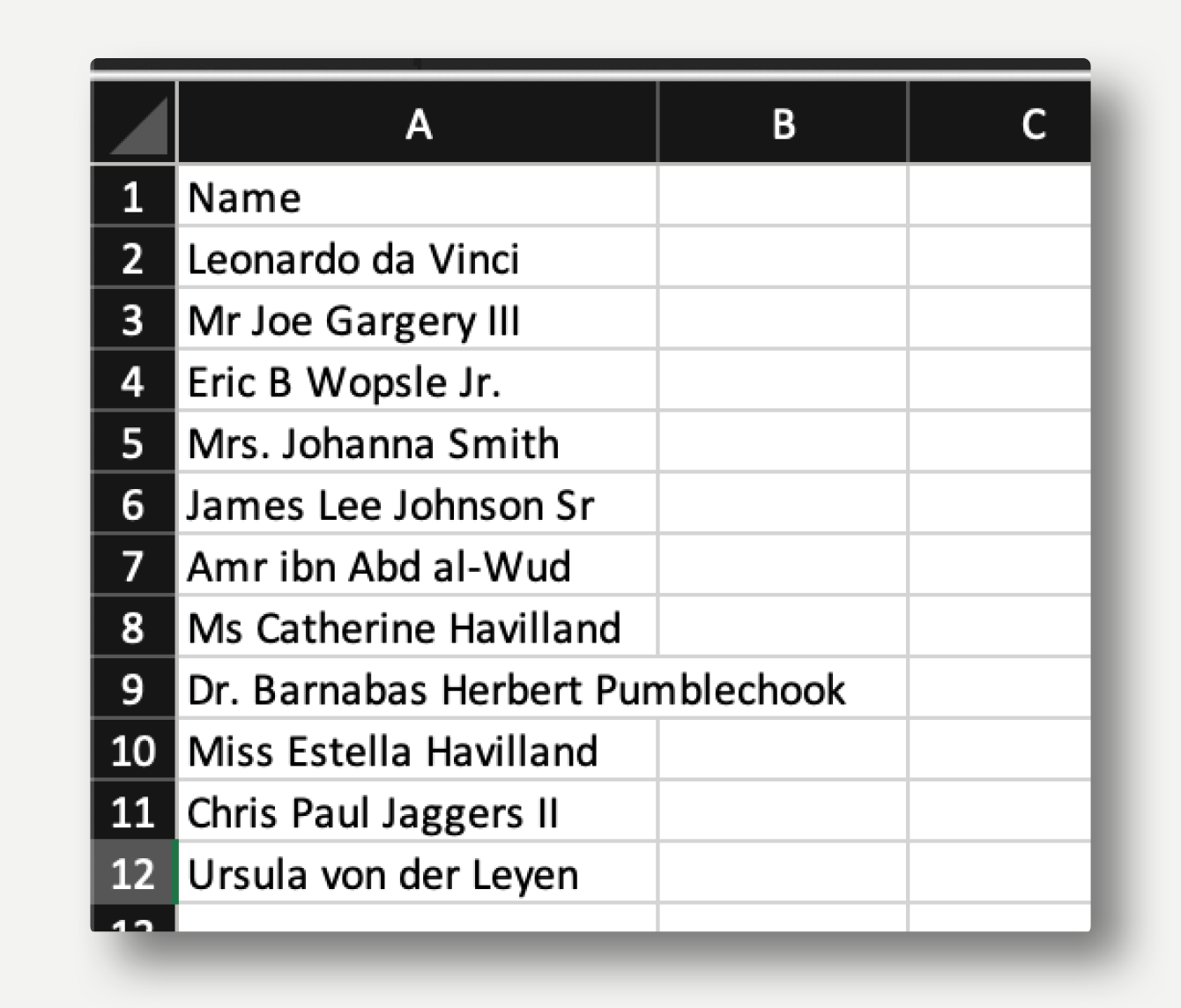
Cleanse and split names of people
Scenario: you have names of people in a single column. The names need to be cleansed to remove Mr, Mrs, etc and split into a two columns of Last Name and First Name.
Input data:
-
All in one column
-
Various prefixes and suffixes
-
Multi-word last names
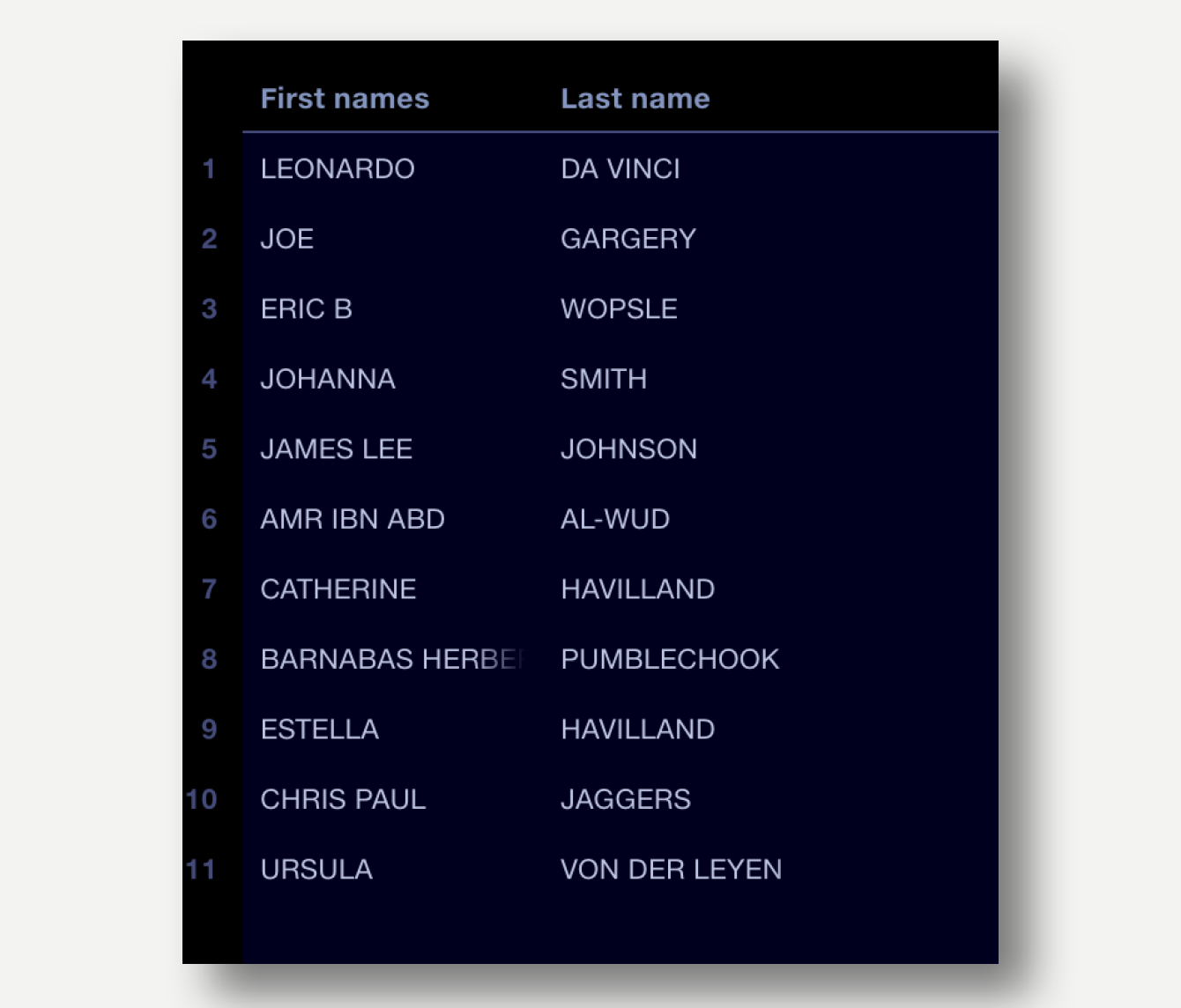
Output data:
-
Suffixes and prefixes removed
-
Split into columns for first names and last name. The first names column also includes any middle names submitted. The process could be adapted to split these into a separate column if needed.
-
Multi-word last names are split correctly
Let’s walk through the steps:
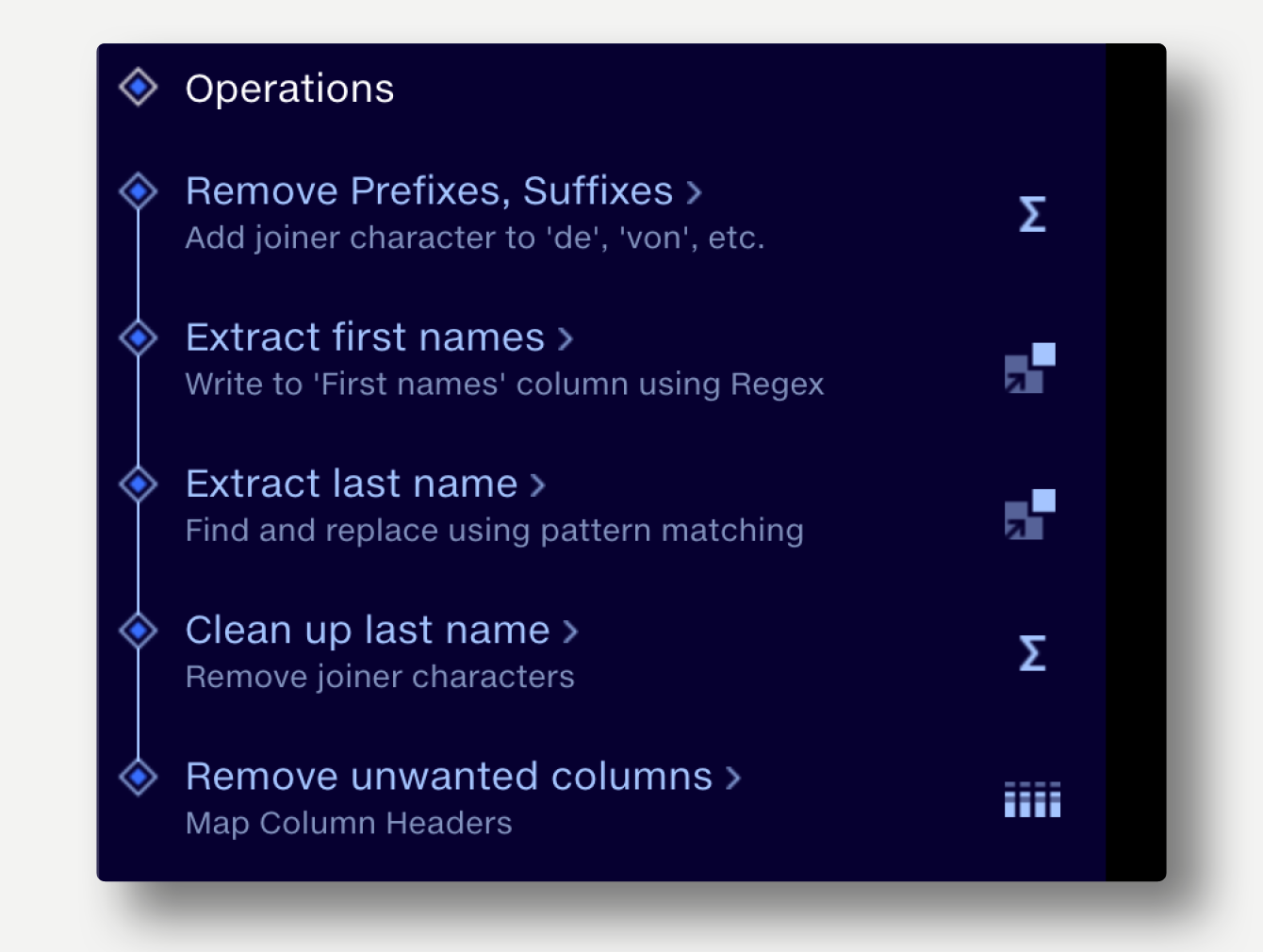
-
Insert a Calculate operation remove prefixes and suffixes
-
Uppercase the names. This reduces the number of permutations required to remove suffixes etc. You could keep it mixed case if required and add the additional permutations:
UPPER('Name')
-
Remove dots from Mr. Jr. etc:
SUBSTITUTE('Name',".","")
-
Remove common prefixes and suffixes (Mr, Dr, Sr, III, etc):
IF(LEFT('Name',3)="MR " or LEFT('Name',3)="DR "or LEFT('Name',3)="MS ", RIGHT('Name', LENGTH('Name')-3), 'Name')
IF(LEFT('Name',4)="MRS ", RIGHT('Name', LENGTH('Name')-4), 'Name')
-
Last names comprising multiple words separated by a space are typically ‘van’, ‘von der’, ‘de’, etc. To deal with them, we identify the types individually and
substitute the space with a ‘#’ character. This allows us to treat the last name as a single word. The # is removed later:
SUBSTITUTE('Name',"VON DER ", "VON#DER#")
-
Extract first names
Using a
Regex, taking first group
(.*) ([^ ]+)$
-
Extract last name
Using the same Regex, taking second group
-
Clean up last name
Calculate operation to remove the # character
SUBSTITUTE('Last name',"#"," ")
-
Finally, clean up the columns. Remove the unwanted ’name’ column using
Map Column Headers. This could be done as part of a more general column clean-up or mapping to output schema later in the pipeline if you wished.
