
A Join stage is used to combine two datasets side-by-side, using one or more matching columns as join points to determine how the rows in each dataset should relate to each other.
The Join stage in Quantemplate accepts two inputs, allows for multiple join points and is able to output multiple combinations of matched and unmatched rows.
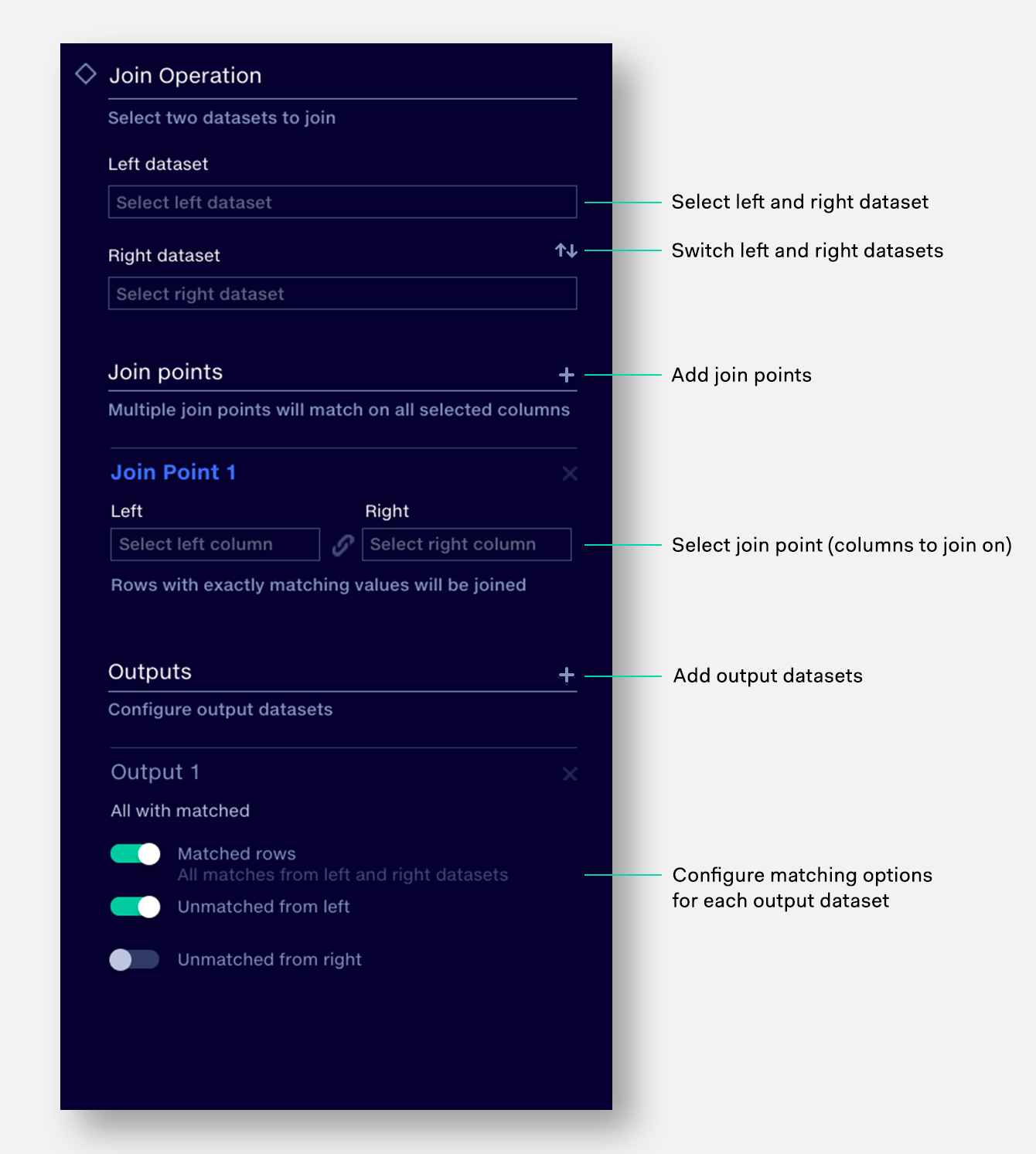
A join stage supports two input datasets, which are then defined as Left and Right. The left dataset will appear on the left side of the output dataset, the right dataset on the right side.
The join point is the column on which the source datasets will be combined. When a value matches exactly in both source datasets, the rows from both datasets will be joined.
Multiple join points can be configured. This allows joining on multiple criteria, for instance when both the Policy No. and Insured Name match.
The join point column appears in both output datasets. Where both sides contain a column with the same name, the column from the right side has the source dataset name appended to it (see example below).
The rows contained in output datasets are configured via three toggles:
This allows the configuration of all standard join types:

Only matched rows from both datasets

Matched rows from both datasets,
plus unmatched rows from Left dataset

Matched rows from both datasets,
plus unmatched rows from Right dataset

Matched and unmatched rows from both datasets

Unmatched rows from both datasets

Unmatched rows from Left dataset

Unmatched rows from Right dataset
Multiple output files may be configured, for instance: one file with the results of a Left Outer Join, plus another file with all the unmatched rows from the join. To avoid creating duplicate output files, identical output combinations will be exported only once.
To configure a join:
KEY |
LEFT |
RIGHT |
Matched row |
||
One-to-many match |
||
Unmatched row |
A dataset of the policies written and their Inception and Expiry dates is configured as the Left dataset in the join.
Policy Ref |
Insured |
Incept |
Expiry |
AB123456 |
General Insure |
1/1/2010 |
31/12/2010 |
AB123457 |
Etc Insure |
1/1/2010 |
31/12/2010 |
AB123458 |
More Insure |
1/1/2010 |
31/12/2010 |
AB123459 |
Less Insure |
1/1/2010 |
31/12/2010 |
AB123461 |
XYZ Insure |
1/1/2010 |
31/12/2010 |
A list of contents amounts is configured as the Right dataset in the join.
Policy Ref |
Property |
Contents |
AB123457 |
5 Main Road |
75,000 |
AB123457 |
1 Highway |
80,000 |
AB123458 |
74 Highstreet |
75,000 |
AB123459 |
24 Chestnut Avenue |
50,000 |
AB123460 |
99 Red Balloon Way |
50,000 |
AB123461 |
12 Grove Road |
60,000 |
AB123462 |
36 Acacia Avenue |
40,000 |
Table 1 and Table 2 are joined on Policy Ref, with the output dataset containing all rows from the Table 1 and matching rows from Table 2. Two matches were found in Table 2 for AB123457, creating two rows in the output dataset. No match was found for AB123456 – a row is created in the output dataset, but the columns from Table 2 are empty.
Note that the Policy Ref column is now duplicated, with the column from Table 2 renamed ‘Policy Ref (Table 2)‘. If desired, this column can be removed via a subsequent Map Columns operation.
Policy Ref |
Insured |
Incept |
Expiry |
Policy Ref (Table 2) |
Property |
Contents |
AB123456 |
General Insure |
1/1/2010 |
31/12/2010 |
|||
AB123457 |
Etc Insure |
1/1/2010 |
31/12/2010 |
AB123457 |
5 Main Road |
75,000 |
AB123457 |
Etc Insure |
1/1/2010 |
31/12/2010 |
AB123457 |
1 Highway |
80,000 |
AB123458 |
More Insure |
1/1/2010 |
31/12/2010 |
AB123458 |
74 Highstreet |
75,000 |
AB123459 |
Less Insure |
1/1/2010 |
31/12/2010 |
AB123459 |
24 Chestnut Avenue |
50,000 |
AB123461 |
XYZ Insure |
1/1/2010 |
31/12/2010 |
AB123461 |
12 Grove Road |
60,000 |
These items could not be matched with a policy number in the first dataset, so may require further investigation.
Policy Ref |
Property |
Contents |
AB123460 |
99 Red Balloon Way |
50,000 |
AB123462 |
36 Acacia Avenue |
40,000 |
Join points must be identical between datasets, including case and whitespace. When a join “fails”, a blank value for that row is returned. If all join points fail, the column name will appear but contain no values.
To increase the likelihood of a match between datasets, it may be necessary to clean up the join points using the techniques outlined in text cleansing.
Free form text values may also benefit from being standardized using Auto Map Values, matching incoming data to a known good value that exists in the corresponding reference table.
Joins cannot be performed on blank cells. Blank entries on the joined column should be set to a value such as “N/A” in both the reference file and the pipeline.
In the join stage, configuring a new output to show “unmatched from left” or “unmatched from right” will help troubleshoot each row that fails the join.
This method will flag rows which have been missed from joins in the validation report, in a way that's easy to understand.
Failure Reason != "Unmatched State"