A Union stage is used to stack multiple datasets vertically, to produce a single output.
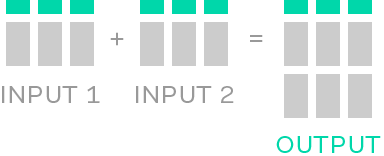
Datasets are combined in alphabetical order (a–z) by filename.
If the column headers of the combined datasets do not match exactly all columns will be included in the output, but only the rows containing data from each input will be populated.
The output file from a union stage is named after the stage itself. This can be helpful for ensuring that when new inputs are brought into a pipeline their data is carried through into subsequent stages.
To union datasets: